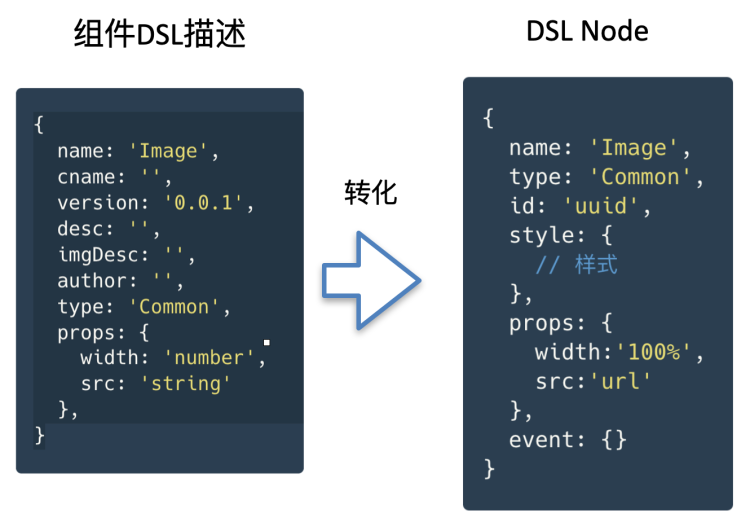
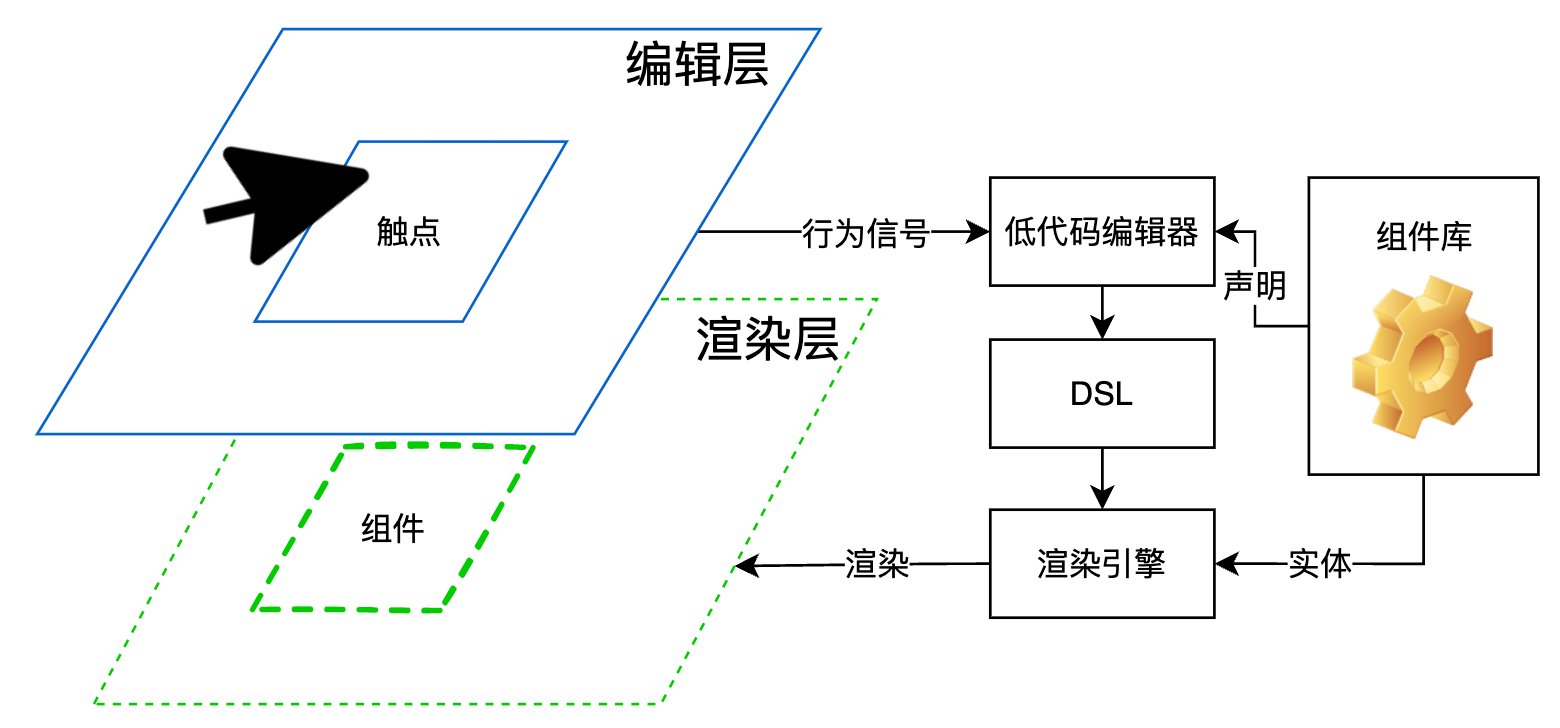
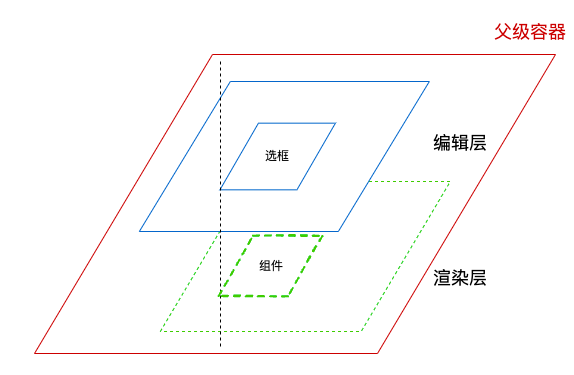
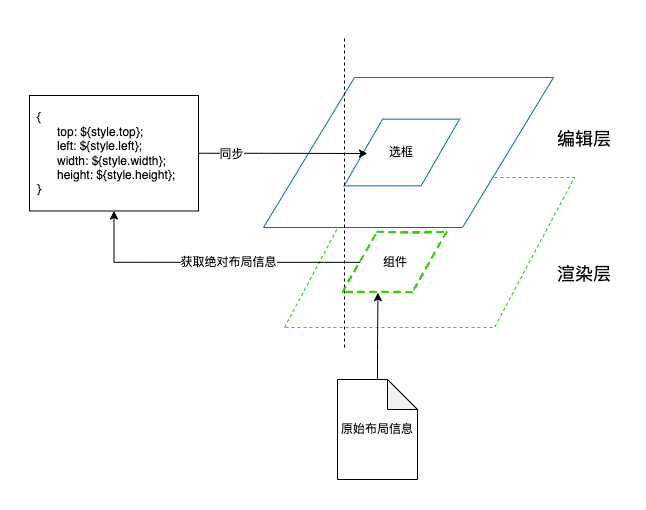
本文内容适用的node版本范围是14+(npm6+),相关例子实在node16+(npm8+)下运行的。
在npm使用还比较初级的时代,如果想做一些项目初始化的脚手架,主要是依靠gulp、grunt、yeoman等工具进行搭建。
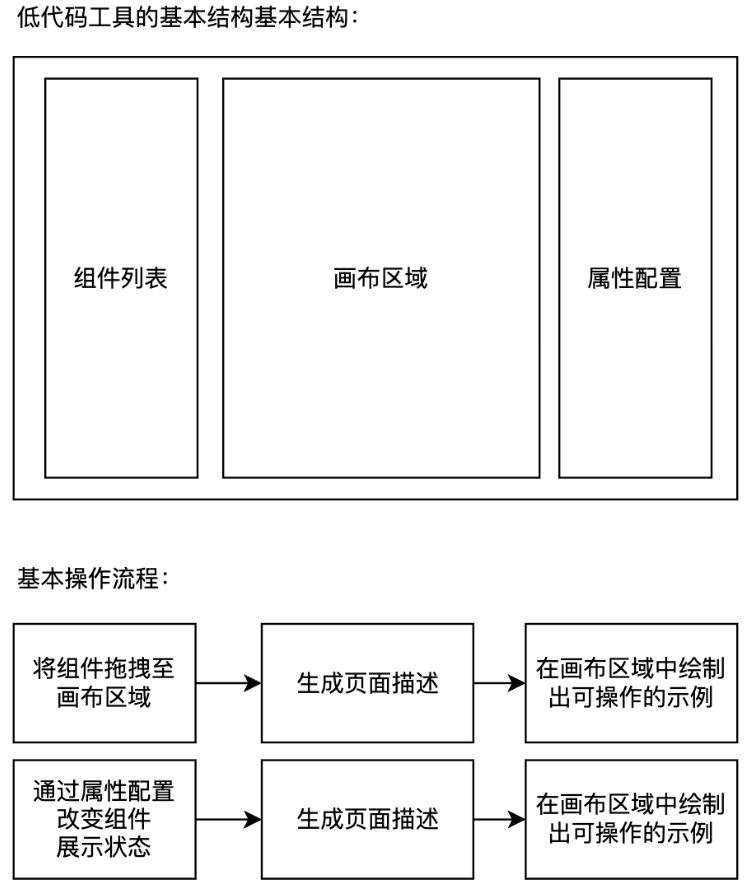
项目初始化,主要是将一套代码的模板(template)进行一系列互动和文件操作,拷贝到用户的项目目录,来进行提效。
而现在我们有了更多更简单的选择,比如npm init。
如果你有一些做项目初始化的需求,那这篇文章应该可以帮到你。
什么是npm init
如果你阅读过create-react-app和vue的官方指引,那再Quick Start中都提到了,一段代码。
# react npm init react-app my-app # vue npm init vue@latest
通过执行这些命令,你会被问及一些问题,根据需要完成后,你就能创建一个react应用或者vue的应用。
这就是文章前面说的,项目初始化。
发现vite用的是npm create
在vite快速创建项目的时候,会发现文档中的命令有些变化。
npm create vite@latest
这里的npm create其实和npm init等价,是个别名
根据npm,version 8版本的文档,以下三种命令是等价的
npm init npm create npm innit
还发现有用npx的
前面提到的create-react-app中,还会看到这样的命令。
npx create-react-app my-app
npx又和npm init有什么关系呢,让我们先来看下npm init的执行逻辑。
npm init是如何工作的
npm init <initializer> can be used to set up a new or existing npm package.
initializer in this case is an npm package named create-<initializer>, which will be installed by npm-exec, and then have its main bin executed — presumably creating or updating package.json and running any other initialization-related operations.
https://docs.npmjs.com/cli/v8/commands/npm-init?v=true#description
npm init的工作方式,其实官网说的是比较清楚的,就是将包名前面加上create-后到npm package中找到对应包,并执行包中配置的bin。
也就是说执行的是npm init vue@latest,实际去找的包其实是npm init create-vue@latest
除了会自动在包名前面加create-去查找,还有一些其他的规则
npm init foo->npm exec create-foo npm init @usr/foo->npm exec @usr/create-foo npm init @usr->npm exec @usr/create npm init @usr@2.0.0->npm exec @usr/create@2.0.0 npm init @usr/foo@2.0.0->npm exec @usr/create-foo@2.0.0
而文档中也很明确的说明了,npm init其实是依赖npm exec去执行的命令,因此你也可以通过npm exec实现所有npm init的能力,就是命令会复杂很多罢了。
传递参数给bin
大家可能知道npm的传参方式,这里以vite举例
# npm 6.x npm create vite@latest my-vue-app --template vue # npm 7+, extra double-dash is needed: npm create vite@latest my-vue-app -- --template vue
从vite文档中给出的命令可以发现,npm不同的版本传参方式还有所不同。
这源于各个版本的process.argv的实现各不相同,npm6会将第一个--解析到结果中,而npm7+则不会在process.argv体现第一个--。
而如果你想让你的用户不感知版本问题可以在代码中做个简单的兼容,将参数统一为npm7+的效果,如:
function removeFirstArgByString(argv, s = '--') {
const newArgv = [...argv];
const i = newArgv.indexOf(s);
if ( i !== -1 ) {
newArgv.splice(i, 1);
}
return newArgv;
}
removeFirstArgByString(process.argv);
深入npm init
文章写到这里,动手能力强的同学,就可以开始对自己已有的复制代码的工具进行一些改造了。
使用命令的时候你也会发现一些现象。
比如在使用这个命令进行项目创建的时候,命令行会先提出一个问题。
npm create vite@latest Need to install the following packages: create-vite@4.1.0 Ok to proceed? (y)
命令行的问题是,你需要安装对应的安装包。
那有经验的同学可能就会有一些问题了:
- 命令行为什么会知道我没有装这个包
- 这个包安装后存到了哪里
- 这个安装包中带了版本号,后续这个包更新了,要如何更新
以前做脚手架的话这些问题是都要考虑的。
而npm init的优势就是在于,将这些问题都考虑到了,即使你不了解这些问题,也不会遇到什么问题。
而为了更严谨,我还是研究了一下这块的逻辑。
前文提到了npm init其实就是基于npm exec实现的,那咱们就看看对应的代码。
https://github.com/npm/cli/blob/v8.19.4/workspaces/libnpmexec/lib/index.js
怎么判断有没有这个包
简单来说,这部分代码的逻辑就是:
- 检查当前路径下是否有目标的包,如果有返回,没有往下
- 检查全局(通过 -g 安装的包)是否有目标的包,如果有返回,没有往下
- 检查缓存是否有目标包,如果有返回,没有往下
- 去当前全局配置的源中招是否有目标包,如果有返回,如果没有报错并结束
通过上面的流程,就能确定是不是有这个包了。
包安装到了哪里
首先你会发现这个包不在你执行命令的子目录下,另外你也会发现这个包也没有存储到全局包的位置。
那这个包去哪里了呢…
他其实在你npm的缓存目录中,通常在~/.npm/_npx中以包名的hash方式命名的目录下存储。
你可以通过npm config get cache来找到缓存目录
已经安装了包,但是包有了新的版本如何更新
前面说了npm已经考虑了这一点,在上面的代码中有一个getManifest方法,在检查包的过程会通过npm的pacote包获取当前源中的最新版本,最后检查缓存中目标包的时候,会check是否是最新版本,如果不是就仍然会提示需要安装包。
其他需要注意的
- 前面提到的示例都没有提到指定版本号
@usr/foo@2.0.0的场景,如果指定了版本,存入缓存的目录名也会带上版本号进行hash处理,因此同一个包的不同版本会分别缓存。 - 另外这里虽然说是缓存,但当前其实并不会被动清理,需要主动去对应缓存目录下清理。
- 如果你是使用
npm i -g的方式安装了create能力的包,就不会走npm init的流程,也就不会检验包是否需要升级,而是需要工具包自己实现这个能力,并且需要自定义一个执行的命令,使用者还需要记一个使用的命令,体验不是很好。
总结
之前都是在使用npm init初始化各个框架,并没有想到是如此方便,如果在工作上有类似的需要,不放赶快尝试一下,为自己和小伙伴提效吧。